Overview
In this blog, I will summarize some non-trivial famous cache prefetch techniques (hardware) in computer architecture. Figure 1 demonstrates the memory hierarchy on modern CPUs. From the absolute access latency for each level, you can see the potential of hardware data prefetching (since usually cache are transparent to software).
|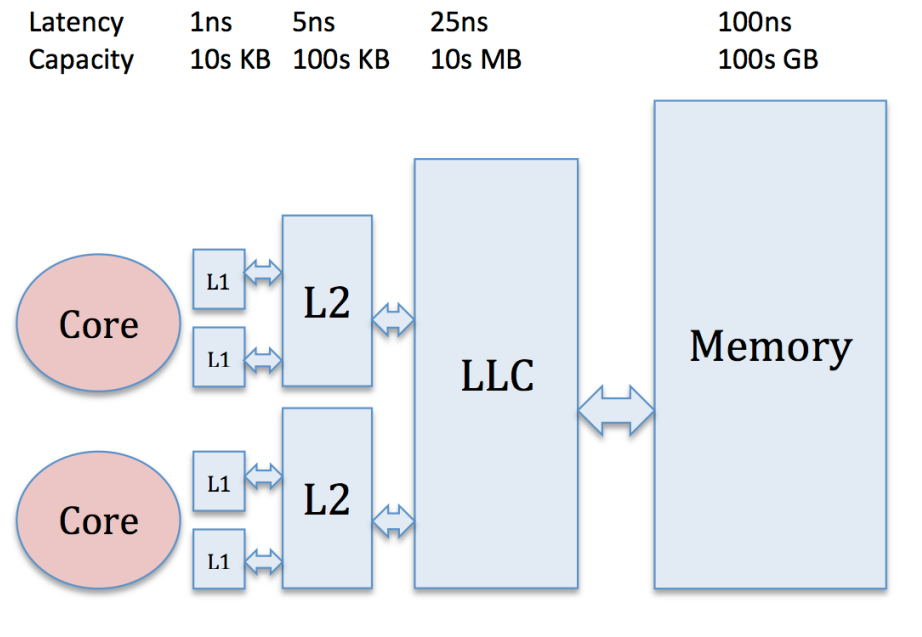 |
|:–:|
| Figure 1 Modern memory hierarchy[1] |
|
|:–:|
| Figure 1 Modern memory hierarchy[1] |
Fundamentals metrics
There are some basic metrics that measure how good a prefetcher is. Prefectch Coverage represents the fraction of total misses that are eliminated by the prefetcher. Prefetch Accuracy is the fraction of total prefetches that were useful. Prefetch degree stands for how much prefetch requests issues (or refered as streams) when prefetch is triggered. Higher degrees yeilds higher bandwidth utilization and potential more capacity miss if accuracy/timeness is not guaranteed.
Policies
In this section, we categorize based on the policy names.
Instruction cache prefetch
Fit cache level: L1 ICache
Since the focus in this blog is data prefetching, here I only use single section to talk about the instruction cache prefetch. Since instruction fetch is most correlated with PC. Thus, it has relatively obvious approach to guide prefetch.
Next line prefetcher is the earliest prefetch techniques that is first use by IBM processor. The idea of next line prefetch is the observation of sequential access of the code (within a routine). So, it can blindly prefetch the next block during instruction cache access. Noted in the actual implementation of prefetcher, it implemented with a small associate buffer (prefetch buffer or stream buffer, basically a single cache set) for the prefetched block. The fetch unit will parallel access the prefetch buffer and L1 instruction cache. This design is common for instruction cache prefetcher.
Another improvement design for instruction cache prefetcher is using branch predictor to guide the prefetch decision, which is obvious since branch prediction has a “future” view of the control flow (non sequential code address in the BTB). Fetch-directed instruction prefetching introduce two buffers, one prefetch target buffer, one prefetch buffer (also a prefetch queue). The prefetch target buffer bridge the gap between branch predictor and instruction cache fetch. The prefetch buffer is parallel accessed with the I cache. Also, the paper mentioned to flush the two buffers when mis-predicts.
The above prefetcher cannot achieve above 95% accuracy. Next line depends on the sequentiality of the code (usually only 50% of the code has sequentiality). Branch prediction guide prefetch limited by the PC (PC can only direct to single branch target address). Thus, simply using PC is not the best idea rather than directly using the instruction cache block address (this is going through the same direction as data prefetching). Temporal instruction fetch streaming uses the pure address rather than PC to guide prefetch. It index the L1 Instruction cache miss address to instruction miss log and can prefetch multiple blocks based on history misses.
In summary, the instruction cache prefetcher is strongly correlated with the code control flow (functional call, return address, etc.). Thus, it has less difficulty to perform very high accuracy for the prefetch (more than 99%). However, due to the much more variety of data access pattern which is correlated to the application itself. Data prefetch is a more challenging and interesting topic which will be covered in the next sections.
Stride and Streaming prefetch
Stride stands for load address stream with fixed offset (next line is a special case). Streaming means prefetch more than 1 blocks in a prefetch stream. Together it forms a class of prefetcher called Stride and Streaming prefetcher. Baer and Chen proposed a prefetcher in this class. It mainly contains a table with PC indexed, including the information of the last load address referenced and stride length (offset) and a single predict bit. When the stride is well trained and predicted, the prefetcher can initiate prefetch on the next stride/s when the load misses and the PC is matched.
Another important aspect of stride and streaming prefetch is the streaming length or prefetch degree/depth. There are ideas to predict the stream length to make the prefetch more accurate.
Stride and streaming method is highly depends on data access pattern. For example, most of the paper use the matrix multiply as an example since it contains multiple loop with strong stride access pattern. For other more complex access pattern like pointer chasing, this will definitely not work.
Best-offset prefetch
Fit cache level: L2 DCache (prefetch from LLC)
Best-offset prefetch is proposed by Pierre Michaud. It’s a hardware friendly implementation of L2 prefetcher. It won the 2nd Data Prefetching Championship. The core idea of BO prefetcher is to always prefetch a fixed offset for demand L2 access. The reasoning of that is based on the program behavior, for example, an matrix access may contain a sequence of stride pattern. The stride pattern can be separated to several access streams with fixed offset. It’s aggressive prefetcher with 1 prefetch depth (higher prefetch depth may require higher LLC bandwidth pressure).
BO prefetch implemented a recent requests (RR) table that records the base address and the offset. The RR table is trained dynamically by iterating different offset. A core implication of BO prefetch is to dynamical tune the prefetch timing which is correlated with the address offset. Consider a stream of fixed offset 1, even though the offset 1 is perfect for prefetching, however, due to timing constraint, a next-line prefetcher may not bring any improvement. However, BO prefetcher can better train the offset to fit the timing requirement.
In the paper, the author also briefly discuss about the prefetch throttling by adding a threshold for offset goodness to turn off prefetching.
SMS
Fit cache level: L1/L2 DCache
Spatial Memory Streaming is a prefetcher designed to exploit spatial correlations of a program. Some typical workloads is database related workload which usually have a fixed memory layout for a memory region (say a page). The memory access will also follow such spatial correlation. For example, read some metadata, then read index, then access some frequently access tuples. SMS records those spatial correlation by an Active Generation Table (AGT) tagged by some high bits of memory address. The table also record PC information for future prediction use. After training the AGT table will get some access pattern (bit vector) associated with a Tag that is combined with PC and some memory address bits. This tag can be used to perform future prediction on cache access.
The paper heavily discussed the evaluation part of how workloads contain those spatial correlation of memory access and how to quantitatively analyze and exploit from those.
If we look closely to the design of SMS, it mainly has two features. First, it exploits the recursive, spatial correlated memory access patterns appears in commercial workloads (such as database, web serving, etc.). Second, it leverages fine grind memory access information (L1 accesses) to train the memory access pattern information. However, this requires monitoring L1 data access which seems to be unrealistic (timing, power, etc.) compared to other prefetcher design (GHB, SPP, etc.) which monitor on cache misses.
B-Fetch
Fit cache level: L1 DCache
Branch Prediction Directed Prefetching is a prefetcher that use branch prediction hints to guide prefetch. The motivation is by leveraging the branch predictor in the front end pipeline, we are able to get the following load addresses (static ones) in the target basic blocks. It sounds like straightforward. However, it requires tightly coupling with front end pipeline (branch prediction, register state, BTB, etc.). The advantage is that it can easily increase prefetch depth with controlled accuracy.(branch predictor can provide confidence information for the program path and a chain of basic blocks can be indexed with a history copy of register states).
Personally, I don’t think this is the right direction for data prefetching. Although front-end provide more information of the program contexts, however, due to the high implementation and timing requirements, the hardware is difficult to implement and prove to be useful. Besides, lower levels of the memory hierarchy are less associated with program contexts. Thus, those prefetcher cannot be used in lower level caches. The memory wall is usually bounded by lower level caches (LLC, DRAM). So, I think the future data prefetcher should focus on pure spatial or temperal address correlations without any front end information.
SPP
Fit cache level: L2
SPP is proposed by Jinchun Kim in our lab. The design of SPP aims at increase of prefetch accuracy by recording more complex access patterns and the ability to prefetch more degrees. SPP introduces a signature table (ST) to record the access pattern within a page. It does some bit manipulation to compress most recent 3 access offset (with some possible aliasing) and form a signature. Then, there is a global pattern table (PT) to record all possible signatures and the following offsets associated with that signature. This PT is important in two sense. First, different offset related to a signature can guide for prefetch path (which next offset is most likely going to happen). Second, the PT can be recursively indexed like chasing pointers by forming new signatures to increase prefetch degrees.
SPP also includes a prefetch filter to remove redundant requests. There is another follow-up paper regarding the prefetch filter by our lab called Perceptron-Based Prefetch Filtering