Overview
In this post, I want to review the important architecture structures related to modern out-of-order execution machine (Tomasulo’s algorithm). Let’s consider a simple RISC pipeline which consists of fetch, decode and register file read, execute, write back (to register file), retire five stages. Below demonstrates the organization of a out-of-order (superscalar) machine. The important structures are register rename table (or register alias table RAT), reservation stations, reorder buffer.
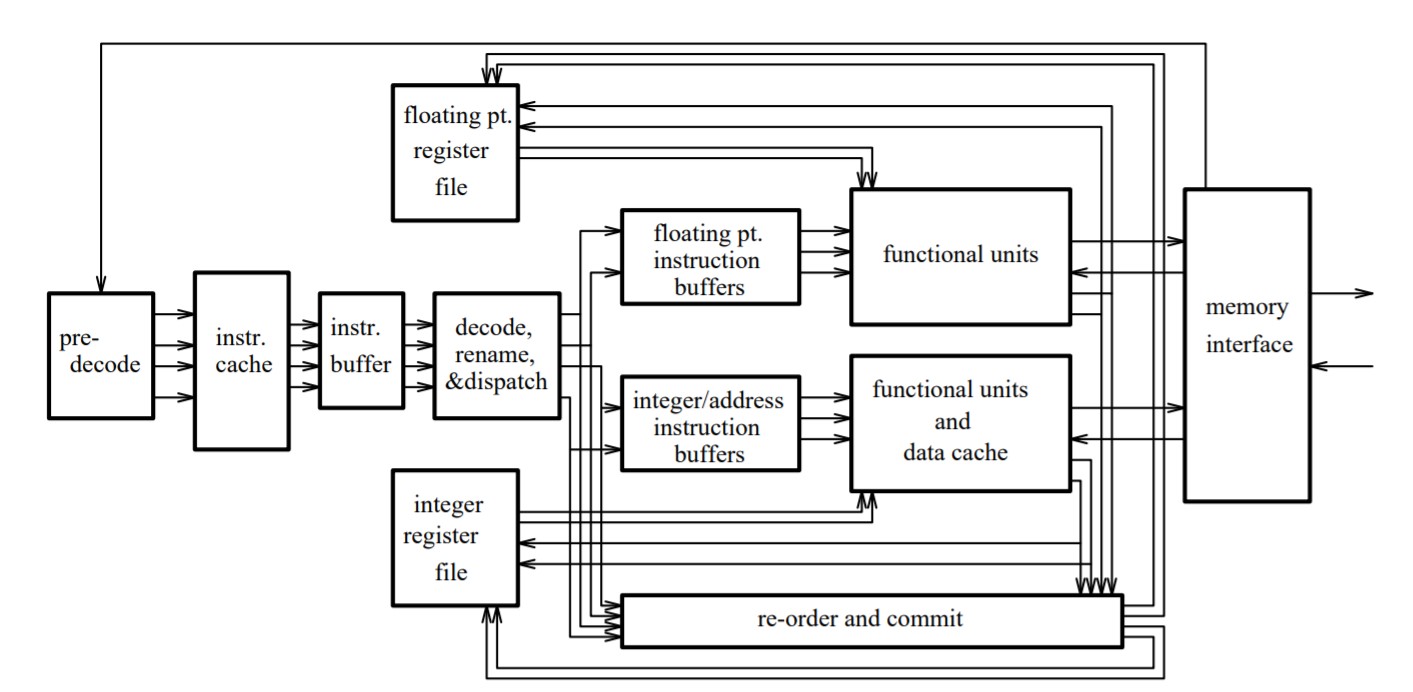 |
|---|
| Figure 1 Organization of a superscalar processor[1] |
Register renaming
Register renaming is the core idea to implement out-of-order execution by dynamically re-scheduling the instructions orders based on dependency.
A easy version for understanding for register renaming is that we have a register alias table (RAT) and multiple reservation stations. RAT actually rename the architecture register ID to a reservation station entry ID (tag).
The RAT will be looks like below. The important fields are tag (reservation station entry ID), value, valid bit. Valid bit unset means that there is an instruction on the fly to write to that register (destination). In the same time, the tag in that entry will monitor the broadcast tag of completed instruction.
| Architecture register | tag | value | valid |
|---|---|---|---|
| R1 | a | don’t care | 0 |
| R2 | |||
| R3 | |||
| … |
Noted that RAT entry size depends on the number of architectural registers in the ISA (not much for x86, 32 for ARM). However, the reorder buffer (instruction window) size can be large (more than 200 in modern CPUs). The RAT entry from previous instruction can be overwritten during the invalid state since the dependency has already been resolved and register has been linked to reservation stations.
The reservation station entry will be look like below. It is composed of two groups of fields for two oprands (source 1 and source 2). The valid bit unset means the register (architecture) is not ready and the tag will be valid for broadcasting the results.
| RS-ID | value | tag | valid | value | tag | valid |
|---|---|---|---|---|---|---|
| a | ||||||
| b | a | 0 | 12 | - | 1 | |
| c | ||||||
| … |
On finishing of ALU computation, the tag (as well as the result) will broadcast to RAT and reservation stations (separate FP/INT) through common data bus (CDB). If matched, the valid bit will be set to the matching entry and value will be captured. Two valid bits set in the reservation station entry means the entry is ready for execution.
Reorder buffer and retirement register file
Reorder buffer (ROB) is designed to support precise exceptions (in-order retirement of instructions). And it can be also useful for flushing instructions before branch mis-prediction. On instruction decode, an ROB entry will be allocated at the head (in order entry allocated). The ROB consists of the following fields. ROB is basically a FIFO, and once the head (or multiple entries from head) is/are finished (not busy or in exception). The entry/entries from the head will be retired (write to retirement RAT).
| ins-type | PC | dst(reg/mem) | value | state |
|---|---|---|---|---|
| branch | ||||
| alu | ||||
| load/store |
Retirement register file or architecture register file (backend RAT) is updated on ROB entry de-allocation (commit instructions). It is used for recover the architecture states.
Physical register file
As you can see, in the rename RAT, reservation station, ROB and retirement RAT, there are all value fields which basically store the redundant register value. So, in modern CPUs (like Pentium 4), there is a unified storage for register file (with many read/write ports for performance reasons) called physical register file. The PRF entry index can be the tag for all those structures as the pointer of the PRF. (reservation station may need a destination tag field for where to write destination register value).
Load/Store
Load/store is a difficult part for out-of-order execution. The main problem is that memory access has dynamic latency (due to the cache hierarchy) and the address calculation latency may differ for a young load and an old store. Basically there are pessimistic and optimistic ways to handle load/store.
The pessimistic way is to process load and store in order. This will avoid any alias and disambiguation. However, it will greatly degrade the performance.
If we think about it, there is little chance that an older store and a newer load collides on the same address during execution. So, an optimistic way is to always issue loads no matter the older stores have been resolved. For each store, after the address is calculated, check back in the reorder buffer to see if there are address collision with newer loads and flush pipeline if needed (we can apply some speculation for).
Optimizations include bypassing and forwarding which requires separate load/store queue. This is also important structures in the OOO processor. Load bypassing basically check the store queue for older stores for address collision. If no collision found (consider the address is resolved), the load can be safely issued. Load forwarding is directly get the value from the store queue if address match on the previous latest stores.