Recently a friend of mine asked me some questions regarding large page. I felt like some of my old knowledge needs to be refreshed on Linux large page practice. Lots of credit to this post, which provides some useful knowledge regarding on how to use large page on Linux.
Paging background
A key component of modern operating systems is paging and virtual memory. The corresponding support on the CPU side is memory management unit (MMU). Paging basically introduces a layer of virtual to physical address translation. On the software side (OS), a radix-tree structured page table serves for the mappings between virtual page number (VPN) to physical page frame (PPF). Thus, the address translation granularity is on the page boundary. (Noted, processor cache line size is normally 64B, so locality still preserves within a page.) In order to accelerate the virtual address (VA) to physical address (PA) translations, basically for every load/store instructions. CPU also implemented corresponding hardware called MMU to conduct the translation by hardware, transparently to software.
The MMU contains a cache of the VPN to PPF entries per process context called TLB. For virtualized environment it’s more complicated, Intel’s manual SDM V3 C4.10 C27 has very detailed description. TLB locates alongside with processor L1 cache. Modern CPUs use virtual index physical tag (VIPT) L1 cache. The TLB is consulted with L1 cache in parallel to minimize the access latency if L1 hits. Another important components in MMU is the page table walker. The CPU vendor will define how the page table structure looks like (with OS vendors of course). After OS fills the page table, through a software trap called page fault, CPU can access the mapping entries (called page table entries, PTEs) without any software intervention.
Why we need large page?
Why all this background matters to large page? Normally for x86 architectures, the page size if 4KB. This size is designed to balance between memory fragmentation, locality and managing metadata overhead. As we mentioned earlier, TLB sits on the very front of the memory hierarchy to cache the VPN to PPF translations, which is critical to the overall memory access latency (AMAT). For all the cache design, capacity is always a limitation. Modern Intel CPUs have around hundred entries for L1 TLB (shared by L1 instruction and data caches). L2 TLB has 1~2 thousands entries. L1 and L2 TLB only cover around 10MB of memory if the translation granularity is all 4KB. Consider a memory intensive workloads (such as graph processing or database), which access a wide range of memory (pages) in a short time. The TLB entries will be constantly missed and CPU needs to constantly walk the page table to fill the TLB. The page walk process can take hundreds of CPU cycles and during this time the CPU pipeline is stalled waiting for the load/store to commit.
To address the above issue, large page (also refers to huge page, super page) is introduced. The concept is pretty straightforward, basically if we have large page size, each TLB entry can cover more memory range. For instance, 8 1GB TLB entries can cover 8GB of total memory which is easily to be fitted in the L1 TLB.
How large page works
If we take a deep look at the page table structure as shown in figure 1 below. If we combine the bits 20-12 (page table offset) and 11-0 (4KB page offset) as the large page offset, we can form a 2MB sized page without significantly change on the paging structure. 1GB large page follows the similar idea. On the page table side, we only need 1 bit (PS) to indicate whether this is a page directory or page table entry (page size). CPUs only need to add a bit extra logic for the page table walker and TLB to differentiate different page size (4KB, 2MB, 1GB).
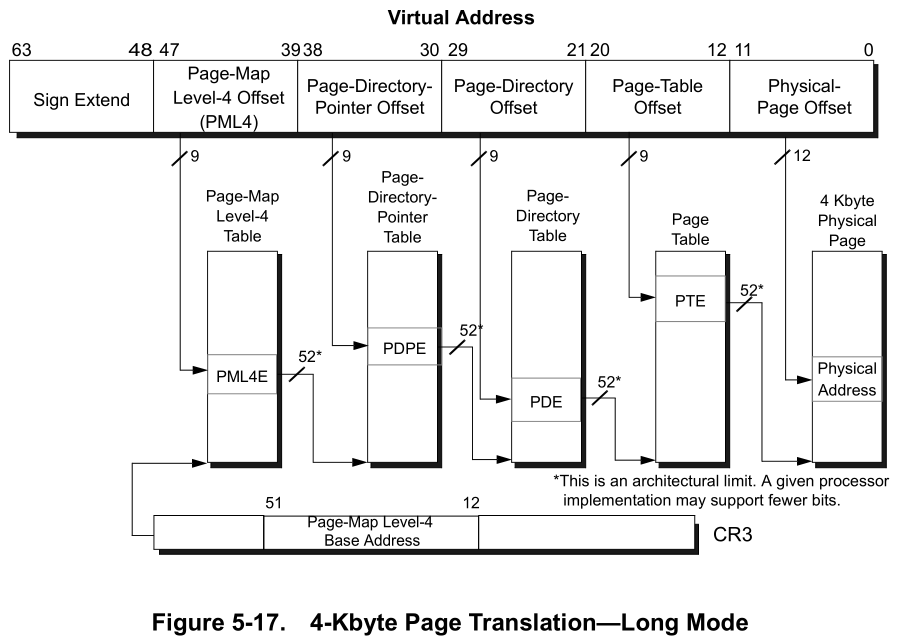 |
|---|
| Figure 1 4-level paging in x64 mode |
How to use large page in Linux
My previously knowledge on large page in Linux limited in transparent huge page (THP) and boot-time configuration (if I remember correctly, how DPDK/SPDK are configured). But it seems nowadays, Linux can also configure large page allocation during run-time.
A challenging of managing large page is memory fragmentation. From the paging discussion above, in order to use large page, the physical page frame must be page size (2M, 1G) aligned as well as continuous. After the system running for a while, there might be no such page left due to fragmentation. So, normally, the system need to preserve some large pages at boot time. The caveat is the amount of memory is waste if no large page is in use. The OS can also try defragment memory to squeeze some large pages. However, this is non-trivial process which requires memory copying, page table updates, TLB shootdown, etc.
Transparent huge page (THP)
Transparent huge page (THP) allows the kernel to automatically manage and promote 4K pages into large pages. You can use madvise(…MADV_HUGEPAGE) to hint the kernel to use large pages for a memory region. (khugepaged will promote large pages in the background)
madvise(base_ptr_, memory_size_, MADV_HUGEPAGE);
Most systems use madvise as default for the THP toggle /sys/kernel/mm/transparent_hugepage/enabled, so that you can use madvise to hint a certain memory region.
If you want to enable THP system wide, you can set the toggle to always.
echo always > /sys/kernel/mm/transparent_hugepage/enabled
Configure large pages at boot-time
Configure the large pages at boot time makes a lot of sense. Kernel will preserve physical memory at early boot time and put the large physical frames in a large page pool. When the applications request large pages, kernel and allocate large physical frames from the large page pool without defragmenting memory, which is a complicated process (memory copying, page table updates, TLB shootdown, etc.) To reserve large pages at boot time, you can add kernel parameters as follows.
hugepagesz=2M hugepages=512
By default, the large page will be evenly distributed to each NUMA nodes in NUMA systems. You can also specify large pages per node by the following (1 2M page on node0 and 2 2M pages on node1).
hugepagesz=2M hugepages=0:1,1:2
Configure large page at run-time
At run-time, large page can be allocated through mmap or shmat/shmget with MAP_HUGETLB. You can configure the large page pool via the following sysfs node.
echo 20 > /proc/sys/vm/nr_hugepages
Or,
echo 20 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
For NUMA node specific configuration, you can configure it here.
echo 20 > /sys/devices/system/node/node0/hugepages/hugepages-2048kB/nr_hugepages
Use large pages through hugetlbfs
Another way to use large pages is through the filesystem interface (hugetlbfs). This is a ramdisk like filesystem, you can either use the conventional open, read, wrire filesystem APIs, or using mmap system call to leverage large pages.
You can mount hugetlbfs with the following command.
mount -t hugetlbfs \
-o uid=<value>,gid=<value>,mode=<value>,pagesize=<value>,size=<value>,\
min_size=<value>,nr_inodes=<value> none /mnt/huge
More information regarding configuring large page/huge page in Linux can be found in this page.
Reference
https://rigtorp.se/hugepages/ https://www.intel.com/content/www/us/en/architecture-and-technology/64-ia-32-architectures-software-developer-vol-3a-part-1-manual.html https://www.kernel.org/doc/html/latest/admin-guide/mm/hugetlbpage.html
Comments
Keep comment service alive. :p